Generative Adversarial Networks for Anime Face Generation — Step by step Tutorial using PyTorch
In recent years, Generative adversarial networks (GAN) become a very popular research field to generate artificial data, especially for image generation.
Many people love anime cartoons and want them to have their own custom anime characters. But to create anime characters needs professional drawing and design skills which are not everyone is capable of. It is important to have a method to generate anime faces without artistic skills.
Today, I am going to explain how to build a GAN model to generate facial images of anime characters.
What is GAN?
Generative adversarial networks (GAN) are popular and powerful machine learning techniques used in image, text, video, and voice generation. since the first GAN introduces in 2014, this research area evolves rapidly, and it remains the most flexible neural network architecture used today.
GAN’s are categorized under unsupervised learning. This is one of the main reasons that a lot of researchers carried out their work using generative models.
GAN’s use two independent neural networks to generate new data, named Generator and Discriminator.
What does Generator Neural Network do?
The generator neural network generates the synthetic data (fake samples) using random noise.
What does Discriminator Neural Network do?
The discriminator neural network acts as a binary classifier and classifies the input sample as real or fake.
Dataset

It is important to have quality data to get quality results.
For this project, I am using Kaggle’s public image data set, Anime Face Dataset NTU-MLDS.
The dataset consists of 36740 high-quality images of anime faces. All the images are colored images with the size of 64 x 64 pixels.
Before starting, Let’s download the data set using Kaggle API
If you are not familiar with Kaggle data download, follow these steps.
Add images to a list and visualize images.
Preprocess and Load the Data
Data preprocessing is one of the main tasks to make sure data is suitable for model training.

First, crop every image at the center and resize the image into 64 with bilinear interpolation, then converts the image with a pixel range of [0, 255] to a tensor object and finally transform the images into values that mean of the image is 0.5 and standard deviation of the image is 0.5. This will normalize the image in the range of [-1, 1].
Define the dataset (AnimeData) and load training images using DataLoader.
Check GPU availability and move data
Here we check whether the computer’s GPU is available and move the data to the GPU (or CPU).
Use GPU to speed up the program.
Define a GAN
Here’s the important part !!!
Neural Network Architecture
As mentioned above GAN architecture contains 2 deep convolutional neural networks to generate images, a generator, and a discriminator. Using noise as input, the generator model is generating “fake” images.
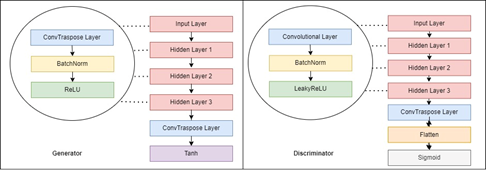
For this project, I am using a generator with 5 transpose convolutional layers, and it will up-sample the input and learn to fill image details during the training process.
Batch normalization was used in the generator model to standardize the inputs to the layers.
Rectified linear unit (ReLU) activation function was used in each hidden layer and Tanh activation function in the output layer.
The output of the generator is the new image as the same size as in the training data samples, 3 x 64 x 64.
The discriminator is also contained with 5 convolutional layers. Similar to the generator, used Batch normalization to hidden layers and LeakyReLU activation function and sigmoid activation function used.
The inputs of the discriminator are 3 x 64 x 64 tensor images, and the discriminator gives a single value as an output which indicates whether the given image is fake or not.
Loss function, Optimization algorithm, and Hyperparameters
Generator and Discriminator networks are trained simultaneously. Loss of both neural networks is calculated using the mean squared error (MSE) loss function.
Optimizers are methods that use to change the neural network attributes such as weight and learning rate. For the initial experiment, I used Adam optimizer for both generator and discriminator neural networks with learning rate, beta1 (exponential decay rate for the first moment estimates), and beta2 (exponential decay rate for the second-moment estimates) hyperparameters.
I found that the model achieves the best performance with 0.0002, 0.5, 0.999 values for learning rate, beta1, and beta2 hyperparameters respectively. I used a batch size of 128 and 40 epochs (iterations) for model training.
You can tune model using different hyperparameter values.
Training Process
Train the neural networks by feeding the preprocessed images to the models. I used 40 iterations in training phases.
Train discriminator
Trained models alternatively, starting with the discriminator. Fed real images to the discriminator and calculate the real loss.
Then generate fake images by feeding noise to the generator and then feed that generator output to the discriminator and calculate the fake loss.
The total loss of discriminator measured as below,
𝑇𝑜𝑡𝑎𝑙 𝑙𝑜𝑠𝑠 = 𝑟𝑒𝑎𝑙 𝑙𝑜𝑠𝑠 + 𝑓𝑎𝑘𝑒 𝑙𝑜𝑠𝑠
Total loss consists of two losses. The first one is to detect real images as real and the second one is to detect fake images as fake. Calculated both real and fake scores by using the mean of discriminator outputs.
Train generator
To train the generator, create fake images by feeding noise to the generator. Then tried to fool the discriminator by using the real loss function (the same real loss function we used to train the discriminator).
Save images
Save the generated images and generator and discriminator models (if you want) at each training epoch. Saved generator loss, discriminator loss, real score, and fake score in every epoch and finally plotted generator loss and discriminator loss in the same graph.
After the end of the first or second training iterations, you will see anime faces appear in the results. Each iteration will improve the model performance.
Generated Images
These are some of the images generated from my GAN model after the 40 epochs. Pretty close right? You can improve these images by tuning the model parameters.


That all !!!
Now you have created your own anime cartoon characters !!!
You can find the full code here.
